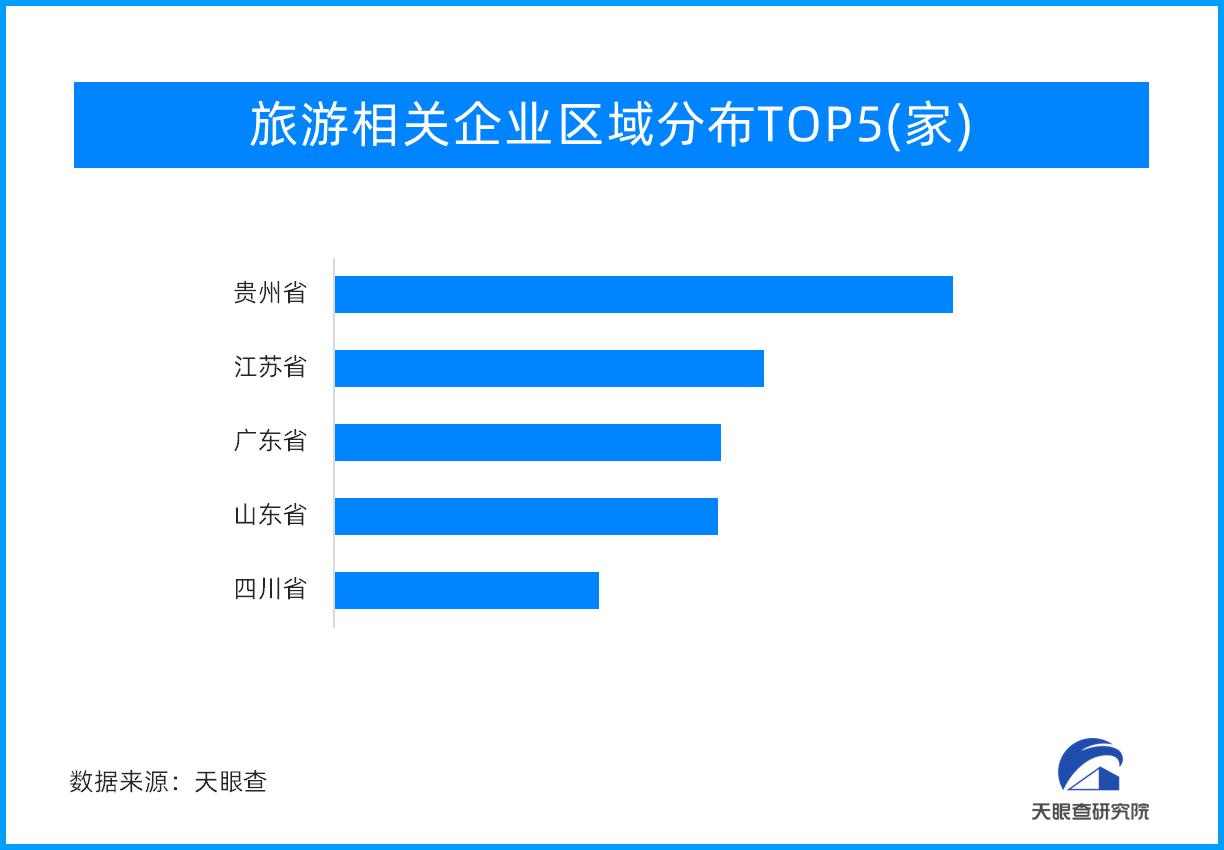
从视觉感知到自主执行,极视角为产业智能体提供视觉基座
2026年,人工智能大模型与智能体正从实验室走向产业现场。巡检机器人、智能安防系统、工业自动化设备等终端被期待能够自主感知环境、理解自然语言指令并精准执行任务。
然而,在实际落地中,大模型智能体应用普遍面临视觉能力瓶颈——无法准确理解复杂背景下的目标、难以根据模糊描述定位对象、无法对画面内容进行推理问答,导致决策失误与任务中断。
当前大量产业智能体所依赖的传统计算机视觉模型,其识别能力局限于预定义的有限类别。一旦遇到训练集中未出现的目标,系统便无法响应。同时,真实产业指令往往包含空间关系与属性描述,例如“那个在第二个路口左转的红色行人”,传统模型难以解析此类自然语言。即便完成目标检测,智能体也缺乏对画面内容的深度理解能力,无法回答“传送带上是否有物品堆积”等推理类问题,从而制约下游决策的可靠性。
在计算机视觉领域深耕逾十年的极视角,自主研发出了星际视觉语言大模型4B版本。据了解,该模型从底层能力设计上针对智能体需求具有八大能力,重点聚焦开放词汇目标检测(OVD)、指代表达理解(REC)与视觉问答(VQA)等关键能力维度。

? 开放词汇检测(OVD)
该模型支持开放词汇目标检测。智能体无需预定义类别列表,输入任意词汇指令,如“损坏的护栏”“违规停放的叉车”,模型即可识别对应目标并输出边界框坐标,覆盖从生活到产业的“万物识别”需求。
? 指代表达理解(REC)
模型具备指代表达理解能力,能够解析包含空间关系、属性特征和行为描述的自然语言指令。例如,对于“那个在第二个路口左转的红色行人”,模型可快速锁定画面中符合条件的目标并输出坐标。这使得操作员可以用日常语言与智能体交互,无需繁琐的坐标编程。
? 视觉问答(VQA)
模型集成了视觉问答能力,可基于当前画面输出结构化信息。智能体能够回答诸如“画面中一共有多少辆车?它们的颜色分别是什么?”“是否有人员进入危险区域?”等问题,所得的数量、属性、状态等信息可直接用于决策模块。
上述能力已在多种产业智能体场景中得到验证。据悉,该模型输出的结构化信息(目标框、属性标签、数量统计、空间关系)可直接驱动下游决策或控制指令。

极视角星际视觉语言大模型4B版本兼顾了小体积与大能力,支持边缘端部署,可在单卡服务器上流畅运行。这一特性满足了智能体对低延迟、数据本地化的需求。
同时,基于10亿以上真实业务数据集的训练,以及细粒度对齐、负样本采样等专项技术,该模型实现了低幻觉和高精度识别。
综合行业趋势来看,随着边缘算力提升和模型轻量化趋势加速,视觉语言模型将成为每个智能体的标准感知组件。极视角星际视觉语言大模型4B版本以“小、准、稳”的特点,已在智慧城市、智慧交通、智慧水务、智慧能源、智能制造等领域获得应用。
声明:本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。文章事实如有疑问,请与有关方核实,文章观点非本网观点,仅供读者参考。